This lesson discusses material from chapter 14. Objectives
important to this lesson:
Big data
Hadoop
NoSQL
Data analytics
Concepts:
Big Data
This is the last chapter to cover in this text. The first
topic is Big Data, which the text has a hard time defining. It seems to
be characterized, but not quantified, partly because hardware and
software solutions keep changing. Things that are hard to do get easier
with better hardware and software, so giving us measurements in the
text would only be good for a relatively short time.
What the author can do is to explain that Big Data is
characterized by being hard to handle in three different ways.
Each of them can be remembered with a word that starts with the letter v:
Volume - This refers to a body of data that is hard
to handle with the available technology because there is so much
of it. The text remarks that Google and Amazon felt this problem early
in their operations due to their success and continuing popularity, and
the volume of data they keep, and that they provide to their increasing
number of users.
Velocity - The text explains that this refers to the
rate at which data is added to and changed in the
organization's information systems. Again, think of a large vendor with
an ever changing set of data that it provides to customers (or the
public), some of which is new, some of which is old, and much of which
must be updated quickly and regularly. The text discusses the Amazon's
ability to track all the items a customer has browsed, in addition to
the ones that were actually ordered. This may help you think about the
increase such tracking causes to volume as well as to velocity.
Variety - This is about having data that does not
have a common structure, which leads to our example
organization having to handle more kinds of data, obtained from many
sources, and stored in a variety of ways. Previously in the text, we
encountered the ideas of structured and unstructured data. Big Data
requires that the system have the ability to process unstructured data,
data that has not been confined to tables built according to business
rules. If the system can apply structures and interpretation of data
when it is searched, it can still be used in the database. A term the
chapter introduces is polyglot persistence, which means the
continuation of using multiple languages. The phrase is not really
about many languages, but about many data types, and many ways of
managing the different types.
The text provides some details about data collected by the
Disney company about each current guest in one of their parks, pointing
out that such data changes continuously during each person's experience
of that park. If makes you wonder about the advisability of keeping Big
Data like that.
As the body of data that needs to be processed continues to
grow, the text discusses two standard methods of handling the increased
load.
Scaling up - Adding RAM and installing better
processors are two classic methods to scale up a system, to increase
its ability to grow by improving existing hardware.
Scaling out - Adding more hardware, such as creating
a new cluster of servers to handle increasing loads, is an example of
scaling out, adding new hardware to improve a system by making it
larger. The text warns that clustering does not fit well with the
design of a relational DBMS, which is based on having a central control
over all the data being processed.
On pages 652 and 653, the text describes two kinds of data
processing that affect the velocity aspect of data.
Stream processing analyzes data as it comes in,
discarding data that is not needed based on functions that have been
preset for the type of data. This reduces the amount of data that will
actually be saved and searched later.
Feedback loop processing analyzes data that is
already stored, asking the user if a particular sort of data is useful,
then using the response to choose what to present to the user next.
This is similar to what happens when YouTube shows you a list of videos
you might want to see next, then modifies the list based on the choice
that you make.
On page 654, the text introduces other factors that add to the
V-problems listed above. Note that they apply to all data processing,
not just Big Data.
Variability - This is different from variety. It
means the degree to which the meaning of data varies, depending on who
is looking at it and why. This is true of all data in general. An
accountant sees an account receivable as an asset, but the manager
restocking a warehouse sees it as money that can't be used by the
business. The text offers an example of a phrase that could be meant
literally by a speaker/customer, or could be meant ironically. A
machine can't tell, but a human may get the point.
Veracity - This is the degree to which we trust
data. Can we trust customer satisfaction scores that are older than
(fill in the blank)? We should realize that some data represent facts,
and other data represent opinions which can change.
Value, Viability - Is the data actually
useful to the organization? Survey results are particularly prone to
error if the survey is not tested on a focus group. If we are
collecting data that is of no use to us, we probably should not be
collecting it, much less analyzing it. Beware of the old warning about
data: garbage in, garbage out.
Visualization - Can the data be presented in a way
that leads to good information? A good chart, graph, or model may help
us recognize a truth that a mere column of numbers may not.
Hadoop
The second section of
the chapter opens with a discussion of Hadoop. Lets get past the silly
name: it is named after a toy elephant belonging to the
son of one of the technology developers, Doug Cutting. Hadoop is a
Java-based technology for handling large amounts of data with clusters
of computers. It is an open source tool of belonging to the Apache
Software Foundation (ASF). It has two major components. Both are
based on papers written by Google employees in 2003 and 2004. (See the
article behind the link provided in this paragraph.)
Hadoop Distributed File System (HDFS) - A
file system that is made to handle terabytes of information
that is replicated across multiple computers. It can support larger
volumes of data as well. Hadoop uses very large data block,
reads entire files as streams, and, according to our
text, writes files that cannot be updated, but may have additional data
appended. There seems to have been an update
to Hadoop to allow file editing, noted
in this online Q/A. Otherwise, changing a file means rewriting
the whole file, not part of it.
Hadoop systems have three kinds of nodes: client nodes,
data nodes, and a name node that manages
connection between client and data nodes. Each file that is added must
have data about its location, and its replicas locations, stored in the
name node. Each data node sends a block report every six hours
to the name node, updating what data blocks are stored on that
data node. Not often enough? Each data node also sends a heartbeat
signal to the name node every three seconds, to let the name node know
the data node is still functioning. A missing heartbeat will cause the
name node to tell remaining data nodes to redistribute data as needed
to maintain multiple data copies.
MapReduce - A model for writing programs to handle
distributed processing of data. In its current form, we can think of
MapReduce as an API that provides support for distributed data
processing. The text goes into a lot of detail that will be interesting
to some of you. We can leave it alone for now.
NoSQL
After the long section about Hadoop and its add-ons with silly
names (Pig, Hive, Impala, Sqoop, Flume), the author remarks that NoSQL
is an unfortunate name. It refers to technologies used to access data
that is not stored in relational databases. Such systems can, in fact,
support SQL in their own way, although none seem to support the ANSI
standard.
Most of the NoSQL products fit into one of four types. The
table on page 663 lists some examples of each type. Don't be surprised
if you have never heard of any of them. These are the types:
Key-value databases - This type of database assigns
a series of keys to particular "values". Value is a poor
word choice. In these databases, the values can be entire documents,
files, or other data types. The pairs are not kept in tables, they are
kept in buckets. There are no relationships from one bucket to
another. Operations specify the name of a bucket and
the name of a key. Three operations are used: get (or fetch),
store, and delete. The text shows an example
of a bucket with three keys, and three key values. It warns us that
this is being displayed in a table, but the actual bucket is not a
table.
Document databases - It is not clear why this is a
separate type. This type uses key-value pairs, but the values
are always documents. More features are available than in
key-value databases. Documents have tagged sections, which may
correspond to particular parts of the document, or to particular
information. Key-values for particular kinds of documents are put into collections,
which are like buckets. (This may sound familiar if you have used a
recent copy of SharePoint.) Operations require a collection
name and a key name to retrieve a document. Tags can
also be used in retrieval operations, using them like attribute names
in SQL.
Column-oriented databases - Confusing as it may be,
the text tells us that this term is applied to two different database
technologies.
The text explains that relational tables are
usually stored in data blocks, each block containing some number
of rows of a table. A column-oriented database will store a
each column of data in one or a few data blocks, which is more
efficient if you are conducting the kind of data processing that
requires you to read entire columns at a time. In a row-oriented
database, that would require you to read the entire file.
The second type of column-oriented database is called a
column family database. Some examples are the
Google's BigTable and Facebook's Cassandra. The example on page 667
shows a less than clear association of some column name and data stored
in separate rows. There are rows? Sort of. There are rows, but rows do
not all hold the same data. If this is giving you the headache it gives
me, take a look at this
blog site about databases. Its author explains that in
Cassandra, rows are the only things that are the same. Follow the link
for more, if you like:
MySQL
Cassandra
Database Instance
Cluster
database
keyspace
table
column family
rows
rows
columns (same in every row)
columns (can be the same, but can be different
in every row)
In this sort of database, columns can be grouped in column families as super
columns. A super column is a group of columns that are related,
like all the columns that hold the part of an address, or all the
columns that hold parts of a customer's name. The text mentions that
you can have super columns or regular columns in a column family, but
not both.
Graph databases - This one is a little hard to
understand from the material in the text. A better short explanation is
found on an Amazon Web Services page, explaining that
you have several nodes/vertices that seem to be instances
of entities. They are linked by directional edges (lines
with arrowheads) that show relationships such as "likes" or
"has", as well as other properties. Take a look at the example
from Amazon, then look at this one from Wikipedia.
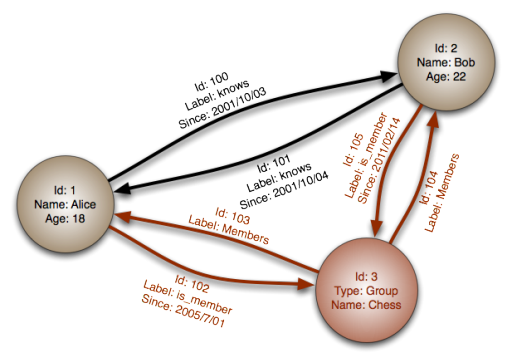
In the example above, you see three nodes that are about two
people and one group. The edges describe the people knowing
each other and being members of the same group. This example is meant
to show the potential for using this kind of database in a social
network environment. In the Amazon example, there is only one edge
between each pair of nodes, but in this one there is an edge going in
each direction between each pair. Now imagine lots of people and lots
of groups in a similarly constructed graph.
This is a pretty good talk about graph databases which is available on
YouTube.
Data Analytics
The last topic in the chapter is a connection back to chapter
13. As it has already been discussed, we can leave it alone.
Assignments for Module 14:
Review all chapters.
There is a numbered Assignment, partially for this
chapter, that began two weeks ago. It is Assignment 8. A link to a Word
document containing the questions can be found in the Module 12 folder for this course on
Blackboard. There are also questions in it that relate to chapter 13.
This assignment is due before class in week
15.
Download the
document, complete it, and save it with a new name that includes your login
ID. This is the version of each file that you should upload for a grade.
Regarding this assignment and all the others, do not simply quote the
material from my notes or the text. Use your own words to show your
understanding of the concepts.
These are individual assignments. Duplicate work will not be counted as
completed work.